Vatic Note: If you are reading this, then you have probably already read the previous two blogs put up tonight on the Windsor/Saxe Gothe family and their corrupt reign over their many commonwealths and how they are already being supported in part by the US taxpayers dollars each year. Further, you read about their corruption and their occult leanings as we blatantly saw by the recent royal wedding and FUNERAL PRACTICE WITH A COFFIN. How occult is that? But most importantly you read about their corruption, and especially their SECRET SOCIETIES. We have discussed the khazars and Queens preoccupation with these practices and for a while I thought they were simply superstitious and marveled how such brilliant psychopaths could be attracted to something as idiotic as "superstition" and the belief in the occult for all these centuries. Well, this below shocked me and gave me a deeper understanding of where these ancient secret societies came from and why they exist and exactly what it is these families pass on to their offspring who are carefully selected for marriage and breeding. It also explained why they murdered Diana and who knows what they have done to her children.
It may also explain why they are so preoccupied with Eugenics. They have spent billions of their foundation money funding such previously thought to be immoral and inhumane criminal subject, for which Dr. Mengeles became a war criminal, but ironically, Rockefeller did not. Hmmm, how did that happen when he funded it... and is still doing so today only at a greater degree than in the past and now the White House and Britain's governments are filled with Eugenicists and its why they could not go through congress for approval. They would have been rejected as viable candidates for serving our government.
I simply thought it was arrogance and high faluting self engrandizement. It wasn't. They protect those bloodlines for the reasons shown below and that is why I put this here so we all could see these connections that I totally missed. Now, after reading this to this point, I have a much better understanding and complete picture of all that secret society stuff. Its how they passed AND CONTROLLED WHO, received the magical "knowledge" they had rather than the superstition I thought they had. After reading those 1st two blogs tonight, and this below... you will know more than 95% of the people on this planet. Amazing what we don't know. Its also info to be used to overcome them. It also explains why they want to collect all that DNA and may well explain how we got 3 to 10 strands of DNA already disconnected. If they do anymore, which they are preparing to do, then the "human race" as we know will be an extinct species, while they make themselves into super beings that can live forever and us as their assets/cattle to serve them without a word of complaint. Frankly, that is the only way they could do that since I just found out that Tyranny has never prevailed once achieved, in the history of mankind. It has always ultimately failed. Now is this below how they plan on over coming that fact??? I don't know, please, you read and decide.
An Ancient and Occult Genetic Code
by Steve Krakowski
1996
from BattleAx Website
http://www.battleax.org/
INTRODUCTION
In the March 1995 issue of "Scientific American", in the article titled "Talking Trash" (see below), scientists claim to have found "word" patterns in the "junk" DNA of man. It seems that this junk DNA (segments of the DNA genome which do not encode instructions for the production of proteins) exhibits the same statistical patterns that are found in written languages.

|
Scientific American
Mar 95
from Dhushara Website
What's in a word? Several nucleotides, some researchers might say. By applying statistical methods developed by linguists, investigators have found that "junk" parts of the genomes of many organisms may be expressing a language. These regions traditionally been regarded as 'useless' accumulations of material from millions of years of evolution.
Junk DNA got its name because the nucleotides there (the fundamental pieces of DNA, combined into so-called base pairs) do not encode instructions for making proteins, the basis for life. In fact, the vast majority of genetic material in organisms from bacteria to mammals consists of non-coding DNA segments, which are interspersed with the coding parts. In humans, about 97 percent of the genome is junk. Over the past 10 years biologists began to suspect that this feature is not entirely trivial.

For instance, studies have found that mutations in certain parts of the non-coding regions lead to cancer. Physicists backed the suspicions a few years ago, when those studying fractals noticed certain patterns in junk DNA. They found that non-coding sequences display what are termed long-range correlations. That is, the position of a nucleotide depends to some extent on the placement of other nucleotides.
Their patterns follow a fractal-like property called 1/f noise, which is inherent in many physical systems that evolve over time, such as electronic circuits, periodicity of earthquakes and even traffic patterns. In the genome, however, the long-range correlations held only for the non-coding sequences; the coding parts exhibited an uncorrelated pattern. Those signs suggested that junk DNA might contain some kind of organized information. To decipher the message, Stanley and his colleagues Rosario N. Mantegna, Sergey V. Buldyrev and Shlomo Haviin collaborated with Amy L Goldberg, Chung-Kang Peng and Michael Simons of Harvard Medical School.
They borrowed from the work of linguist George K. Zipf who by looking at texts from several languages ranked the frequency with which words occur. Plotting the rank of words against those in a text produces a distinct relation. The most common word "the" in English occurs 10 times, than the 10th most common word, 100 times more often than the 100th most common, and so forth. The researchers tested the relation on 40 DNA sequences of species ranging from viruses to humans.
They then grouped pairs of nucleotides to create words between three and eight pairs long (it takes three pairs to specify an amino acid). In every case, they found that non-coding regions followed the Zipf relation more closely than did coding regions, suggesting that junk DNA follows the structure of languages.
You can't have any mistakes in a code. Language, in contrast, is a statistical, structured system with built-in redundancies. A few mumbled words or scattered typos usually do not render a sentence incomprehensible.
In fact, the workers tested this notion of repetition by applying a second analysis, this time from information theorist Claude E Shanon who in the 1950s quantified redundancies in languages. They found that junk DNA contains three to four times the redundancies of coding segments. Because of the statistical nature of the results, the researchers admit their findings are unlikely to help biologists identify functional aspects of junk DNA. Rather the work may indicate something about efficient information storage.
Another speculation is quences may be essential to the way DNA has to fold to fit into the nucleus.
Some researchers question whether the group has found anything significant. One of those is Beniot Mandelbrot of Yale University. In the 1950s the mathematician pointed out that Zipf's law is a statistical numbers game that has little to do with recognizable language features, such as semantics. Moreover, he claims the group made several errors.
But such criticisms are not stopping the Boston workers from trying to deciphers junk DNA's tongue.
|

A number of years ago I stumbled across a unique similarity of form between the genetic code and a fusion of the Hebrew alphabet with the ancient Chinese divination system of the I Ching, or "Book of Changes." I was studying the I Ching when I came across a book(1) that demonstrated an isomorphism between the 64 symbols of the I Ching (called hexagrams or kua) and the 64 codons of the genetic code. I wondered if there might be, among the mystic or occult systems of other cultures, a corresponding set of symbols for the amino acids of the genetic code for which the 64 codons code. I turned to the Hebrew occult system of Qabalah and discovered the Sefer Yetzirah or "Book of Creation."(2)
The Sefer Yetzirah is the earliest known text of the Qabalah. Its "magical" purpose is to educate the reader in the process of creation using the Hebrew alphabet as The Creator did. Because the 22 trump cards (also called atu) of the Tarot system of divination have Hebrew letters assigned to them, I thought that maybe I could compare the symbols, images, and concepts in the Tarot trumps with the corresponding contents of the I Ching kua. Then, if there are enough similarities, I could assign each of the trumps to a group of I Ching kua. The result would be a Hebrew letter assignment for each amino acid and punctuation codon in the genetic code.
TABLE OF THE UNIVERSAL GENETIC CODE
PYRIMIDINE NUCLEIC ACIDS PURINE NUCLEIC ACIDS
URACIL CYTOSINE ADENINE GUANINE
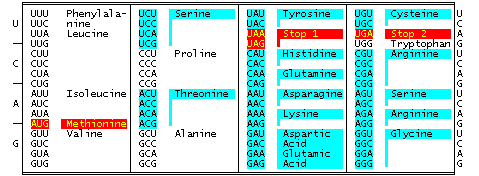
Chart 1
The codons for the amino acids read from left-top-right.
Red=Punctuation
White=Non-polar
Blue=Polar amino acids.
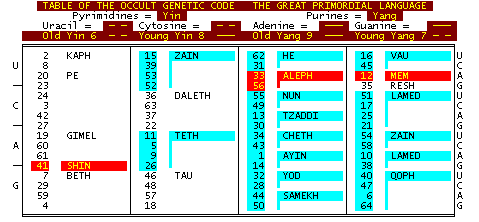
Chart 2
I Ching kua chapter numbers are assigned to the codons and Hebrew letters to amino acids.
Red="Mother"
White="Double"
Blue="Simple" Hebrew letters.
The assignment of the I Ching symbols to the nucleic acids of the genetic code is based upon similarities of form and function between their respective domains of knowledge. The assignment of Hebrew letters to the groups of I Ching kua is based upon the similarity of content between the atu of the Tarot and the kua of the I Ching. The Hebrew letter PE, on the Tarot atu "The Tower", is assigned to the I Ching kua 20, 23, 24, 3, 42, and 27 because the symbol, image, and concept content of the atu and kua are similar to a high degree. As a result, PE is analogous to the amino acid leucine because the kua assigned to it are analogous to the codons which code for leucine. I used the Wilhelm/Baynes(3) translation of the I Ching and Aleister Crowley's "Book of Thoth,"(4) his interpretation of the Tarot. I didn't think that I would find too great a similarity between these two divination systems since Wilhem's I Ching is derived from the very moralistic Confucian school of Oriental philosophy while Crowley's Tarot is a vehicle for his highly idiosyncratic and minimally moralistic system of "sex magic" as a path to enlightenment.
Imagine my shock and surprise when I discovered that these two diverse approaches to divination, one Eastern and one Western, demonstrated an enormous similarity of content; symbolic, imagistic, and conceptual - WHEN GROUPED AND ARRANGED AS THE NUCLEIC ACIDS AND AMINO ACIDS ARE GROUPED AND ARRANGED IN THE GENETIC CODE.
I couldn't shake the idea that these two symbol systems may be vehicles for the transport of two halves of what may be a textual virus - set to infect the body politic of Earth at a time when that knowledge is needed. Perhaps somewhere in the vast genetic library that is the human genome there is a clear message, in the Hebrew or a precursor language, from "The Creator(s)."
If "The Creator(s)" have a sense of humor similar to ours, maybe they would get a kick out of the idea of letting us know, at a future time when we are technologically advanced enough, just who we are and how we came to be.
BIBLIOGRAPHY
1 "The I Ching & the Genetic Code - The Hidden Key to Life"; Martin Schonberger, 1979 2 "Sefer Yetzirah - The Book of Creation"; Aryeh Kaplan, Samuel Weiser, 1990 3 "The I Ching or Book of Changes"; Richard Wilhelm translator, rendered from the German into English by C.F. Baynes, 1976 4 "The Book of Thoth (Egyptian Tarot)"; Aleister Crowley, 1979
CONTENTS
-
Why the I Ching symbols are like the codons of the genetic code
-
Why the letters of the Hebrew alphabet are like the amino acids of the genetic code
-
A new way of looking at the I Ching divination procedure.
-
How the new divination procedure for the I Ching models the process of protein production
-
A summary of the biological and divination analogies
-
Occult Genetic Code Table - by using it, find each of the Trump/Hebrew letter assignments to their respective amino acids and why they are so
-
I Chin Table - Exagrams
The article is reproduced in accordance with Section 107 of title 17 of the Copyright Law of the United States relating to fair-use and is for the purposes of criticism, comment, news reporting, teaching, scholarship, and research.
2 comments:
I had always believed that something is written (literally) in our dna. May I suggest to try using the arabic language.
Umberto Eco wrote that some linguists are fascinated by the idea of an Adamic language--that is, a first language, from which all other languages are descended. He suggested that the words of an Adamic language, unlike the seemingly arbitrary words we use today, would express the essence of what the word means. I suspect that the expression, "Wow," which, in Chinese, is said, "Wah," is an example of an Adamic expression. I seriously believe that "Wah" more accurately expresses the meaning than "Wow" and would be closer to being Adamic.
If language is encoded in the human DNA, I suspect that it would be Adamic.
Post a Comment